Does this even need saying? That I should even feel moved to write this post, in this day and age, seems extraordinary. But an increasing number of people are latching onto the hoary old idea that there is no such thing as a virus - that virologists have been studying an artefact all this time; a product of the organism rather than an entity hijacking host biology in order to spread between hosts. Or, madder still, the whole field is a 130-year fraud, perpetuated by generations of scientists in order to ... ummm ... something something.
Like many positions over the last few years, it is driven by Covid denialism taken to extremes - not only does SARS-CoV-2 not exist, none of them do. This seems a somewhat hyperbolic extension - scepticism over SARS-CoV-2 extended to dismissing the entire science of virology! This puts me in mind of the inhabitants of the planet Krikkit in Douglas Adams's Hitchhiker's Guide upon observing the glories of the Universe for the first time above their cloud-shrouded planet:
When I was a kid at school, I was told to 'spice up' my daily diary, so I said I'd seen a tiger. I couldn't understand why everyone laughed: how could they possibly know? Virus denial puts me in mind of my restricted worldview at that time: to anyone with a grasp of molecular biology, it seems a ridiculous position to espouse. It can only be sustained through ignorance. Because not only is germ theory denial at odds with the understanding of the nucleic acid-protein relationship that developed in the latter half of the 20th century, viruses directly contributed to that understanding. It was a virus that gave some of the earliest evidence that nucleic acid was the genetic material. Viruses infecting bacteria - bacteriophages - had vital roles in elucidating the genetic code, in understanding the control of gene expression, and in genetic engineering. A virus was the first 'organism' to have its genome sequenced. The literature is full of TMV, ΦX174, T4, T7 and λ. All of this was only possible because they are clearly an entity separate from the organism they infect - in all but one of those, the 'model' bacterium Escherichia coli. Their genes are different, their proteins are different, they can be purified, crystallised, caught or interrupted in the act of infection... yet these people would have it that no virus has ever been 'isolated'.
One might forgive online contrarians their ignorance. People classically do not know what they don't know, just as my tiger seemed a plausible fiction to me. Among scientists, though, molecular biology and genomics should have killed the idea stone dead, yet a number of people with a publication history in relevant fields have latched onto this. Among them are Stefan Lanka and Mike Donio. Both have published papers in their earlier careers that are quite orthodox. Here's Lanka with a 1993 paper on the genome of a virus of marine algae. Donio, meanwhile, co-authored this paper on co-occurrence of Guillain-Barre virus and HIV, among others. Something must have caused an epiphany. Donio has now taken to Tweeting, almost daily: "Today is [...] and there still is no evidence that viruses exist!".
A potted history
Viruses were first suspected in 1892 when Dmitri Ivanovsky demonstrated that 'something' in sap from infected plants was able to transfer tobacco mosaic disease to healthy plants after passing through filters fine enough to exclude bacteria.
In 1896, Ernest Hankin noted that 'something' in the waters of the Ganges, again able to pass through a fine filter, had a marked detrimental effect on the cholera bacterium. He had discovered the first bacteriophage.
The agents underlying these observations, whatever they were, were invisible to light microscopy, so remained speculative. At that stage, it was not possible to rule out the possibility that the phenomenon was due to some chemical agent in solution. So in about 1900, virus denial would have been a perfectly respectable position! But with the developments in electron microscopy and x-ray crystallography (only possible if a substance can be 'isolated' and purified) during the first half of the 20th century, we were finally able to visualise these agents, while developments in biochemistry enabled detail of their protein and nucleic acid components to be examined, as well as providing materials for investigation into the fundamentals of biochemistry itself. For example, plant viruses were observed to provide a useful source of pure RNA - a chemically difficult separation using whole cells due to the close similarity of DNA and RNA - as far back as the 1930s.
In the first half of the 1900's, it was not known whether protein or nucleic acid carried the genetic material. Two landmark experiments, familiar to anyone who has ever taken a molecular biology class, established that it was definitely nucleic acid. Firstly,
Oswald Avery in 1944 showed that the material causing transformation in pneumococcal bacteria - making infectious particles from uninfectious components - was most likely DNA. However, they could not discount the possibility of microscopic impurity. The matter was largely settled by
Alfred Hershey and Martha Chase in 1952
using viruses. Bacteriophages have a protein coat with nucleic acid inside. By separately labelling proteins with radioactive sulphur, and nucleic acids with phosphorus, they established that, on infection, the protein stayed outside the cell and the nucleic acid went in, causing the subsequent death of the cell. Later, tobacco mosaic disease was shown to be caused by its RNA component alone, indicating that plant viral infection, at least, had a similar basis to phage-induced cell death.
Within a year of Hershey-Chase, the Watson-Crick structure of nucleic acid was published, with its famously laconic observation
"It has not escaped our notice that the specific pairing we have
postulated immediately suggests a possible copying mechanism for the
genetic material."
This 'pairing' refers to the pairwise affinity of the 4 DNA bases for each other: A binds to T, and G binds to C. Thus, if you know the sequence of one strand, you automatically know the sequence of the other. You can use the one as a template for the other. More than that: a template is always used. Barring occasional single-base insertion, or monotonous polynucleotides, any nucleic acid sequence always ultimately derives from template-directed synthesis, not from stitching together bases de novo. This is important for the question 'are viruses real?', as we shall see.

Further progress was made by Crick and others in the elucidation of the genetic code, the set of 64 different triplets that specify the amino acid sequence of proteins. This work made elegant use of a virus, bacteriophage T4, to establish that the code was triplet in nature. In these pre-sequencing days, the work relied upon a prior map of the 'phage's genome derived by Seymour Benzer. This map itself was only made possible by the way in which the phage infects its hosts - phages are not simply breakdown artefacts, as deniers suppose viruses to be.
Following this, the coding table was gradually filled in by Nirenberg - first the easy ones, poly-U etc, then simple alternates giving 2-acid mixtures, and so on. The triplet code was thus independently confirmed.
In parallel with this work, viruses contributed to a fuller understanding of gene expression control. A gene in DNA consists of a sequence transcribed into RNA, but flanked by 'upstream' and 'downstream' sequence that is not transcribed. The RNA is processed before being translated into protein, 3 RNA bases coding for each amino acid. Again 'upstream' and 'downstream' sequence is not translated, but is required for proper processing. Without these flanking sequences, the gene does nothing. Much of this picture came initially from studying and utilising viruses.

"Ah", says the denier. "I accept the existence of bacteriophages, so you've wasted your time". But why? What is fundamentally different about bacteriophages? Is it simply that they are harder to deny? By what criteria do you accept the 'isolation' of phages infecting prokaryotes, but reject that of viruses infecting eukaryotes? It's fairly easy to see phages in action. You can use a cell counter, and observe the bacteria blebbing out in real time, as they burst forth their cargo of replicated virions. But then, you can do similar with single-celled eukaryotic protists. It becomes a shade harder with multicellular organisms, but not much. Point is, the techniques and observations in use at a level one does accept are different only in detail from those used at a level one does not. I think this is why people latch onto a 'hardline' version of virus denial. Concede on one, there's a foot in the door and you have to let 'em all in!
It is not simply bacteriophages that have contributed to the above understanding. For example, in determining that eukaryotic cells process mRNA,
poliovirus was used, specifically because it
multiplies in
HeLa cells, and redirects their protein synthesis to itself. It is not a breakdown product of those cells. Similarly, DNA viruses herpes simplex and mouse virus SV40 (which integrates into chromosomes) were used to investigate the path from nuclear RNA to cytoplasmic processing, and indicating the mechanisms by which viruses can cause cancers. Vaccinia virus gave the earliest indication that mRNA acquired a 'poly-A tail' - a very useful 'handle' for grabbing hold specifically of mRNA for further investigation. Other viruses such as vesicular stomatitis virus, reoviruses and adenovirus also helped supply key elements of the emerging picture, in a manner that depended entirely on their cellular infectivity and reproduction.
Are we to suppose that these scientists were all completely misled by artefacts? One wonders how molecular biology survived these errors!
Genome or 'genome'?
Virologists think they recover viral genomes from sick patients. Deniers do not. And here's the nub of the problem: if the virologists aren't looking at 'real' viral genomes in the disputed part of the set, what are they looking at? Some argue that these 'pseudogenomes' are an artefact of extraction, constructed from the host DNA. This is highly implausible. These 'pseudogenomes' have a consistent size and structure for a given virus, nonetheless distinct from those produced by other viruses: for a given species the same genes appear in the same order with largely the same internal sequence. Yet among those distinct constructs, there are relationships. The 'coronaviruses' cluster together, the 'rhinoviruses' likewise, while even within a given cluster different variants appear. It looks for all the world like a nested hierarchy: a product of a branching process of replication. Why would a process of host DNA randomisation produce a nested hierarchy? You would expect every instance to be different, random, and be more closely related to the host genome than to each other.
Furthermore, some of these 'pseudogenomes' are RNA, some DNA. So we need two sets of processes here: one to reassemble DNA in the nucleus, the other operating on RNA transcripts. Within that, we need mechanisms to separately construct adenovirus, rhinovirus, coronavirus, rabies, etc etc.
These hypothesised reassemblies also need to generate viable functional genes - because the genes of viruses
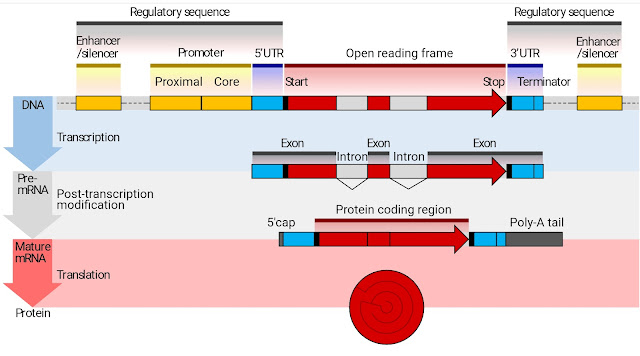
are functional. They can be transcribed (DNA viruses) and/or translated (both) into a consistently folded protein product indistinguishable from that appearing in an intact virion. As we can see from the picture above, a DNA gene needs specific control sequences in order to be translated at all, and it needs to contain control sequences for subsequent processing when it has been copied into RNA. There's even the restriction that the first triplet a specific distance downstream of the control sequence is AUG. Getting this tight specification from random assembly is a tall order - like getting the bitmap of a horse, and the header detail that tells the rendering software what it's looking at, by flipping coins.
Yet there is absolutely no evidence of such reassembly. Bear in mind that, as noted above, a nucleic acid strand always derives from a template somewhere. There is no known mechanism that generates non-monotonous stretches of nucleic acid without using a template, or which obliterates all information regarding that template in the process. DNA sequence always comes from prior DNA/RNA sequence, RNA likewise, even when there is recombination. Yet there is little or no sequence similarity, even fragmentary, with the host. Conversely, there's a great deal of sequence similarity with other instances of the viral sequence. So why not infer that they have a common origin with each other? It is far more likely ... surely?
There is an echo of arguments with Creationists in all this. If I see a host of nucleic acid strings of common sequence, forming nested hierarchies, my go-to explanation is that these are most likely commonly descended, by template copying. This is the general principle behind molecular phylogenetics, which establishes relationships between species using genes, and also can be used to track diseases. In both cases, accumulated inherited copy errors allow the inference of the branching trees of descent. But no, these latter-day Creationists would have it, these genomes are 'separately created' from the host in some way that nonetheless generates functional genes and clustered nested hierarchies.
If your hypothesis demands an unknown mechanism to keep it afloat, and ignores a more obvious, known cause, so much the worse for your hypothesis. On the other hand, if such a mechanism were discovered, there could be a Nobel in it. Leading lights of the 'no-virus' movement seem more interested in issuing
theatrical monetary challenges to the mainstream than in investigating this corollary of their anti-hypothesis. In John Baez's prescient 1998 'crackpot index', that's a 10-pointer.




Comments
Post a Comment